InfoNCE Induces Gaussian Distribution
ICLR 2026, Oral




* Equal contribution
* Equal contribution
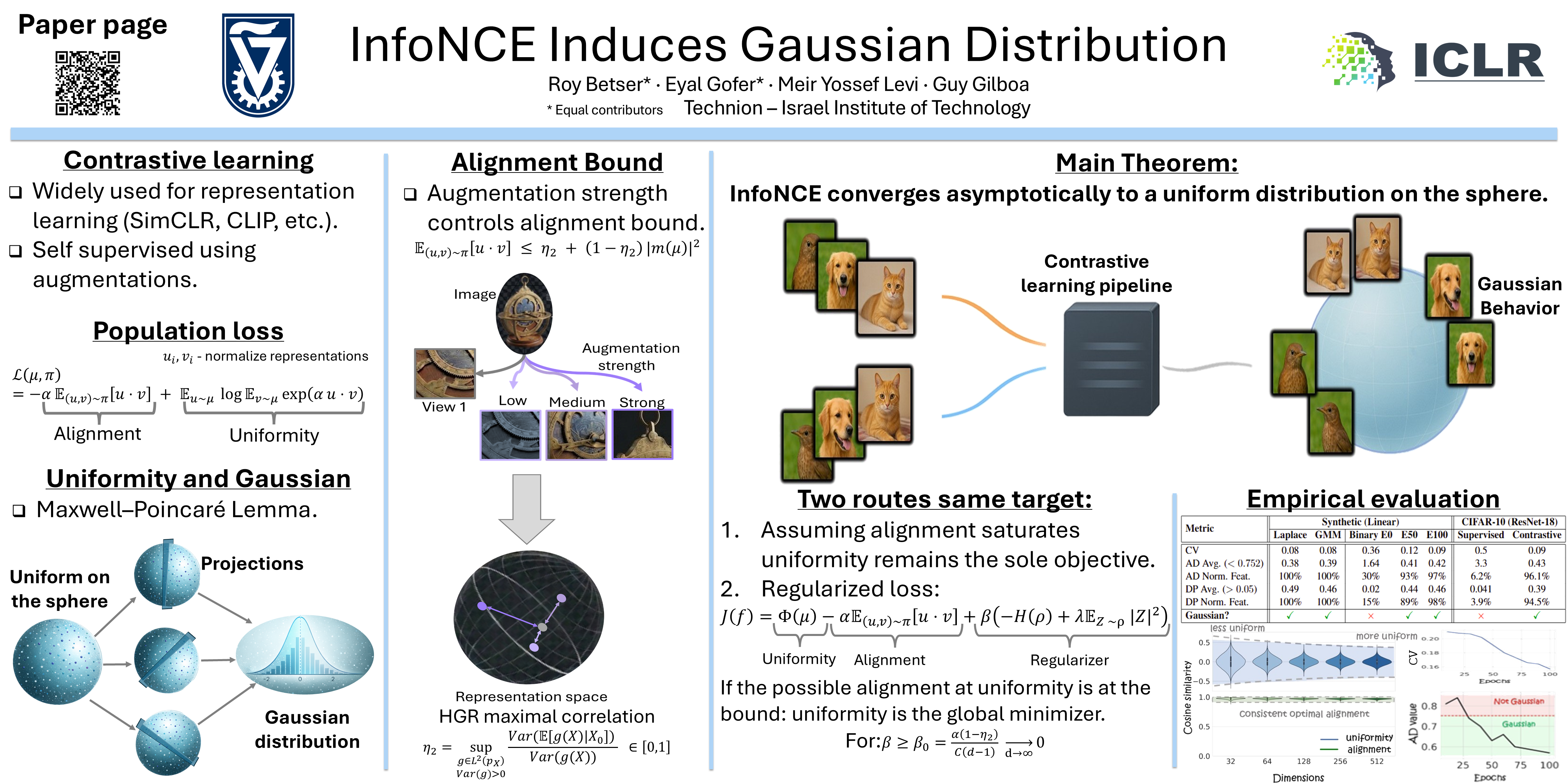
Contrastive learning has become a cornerstone of modern representation learning, enabling scalable training on massive unlabeled data. We show that the population InfoNCE objective induces asymptotically Gaussian structure in representations that emerge from contrastive training, and establish this through two complementary analytical routes. We support the analysis with experiments on synthetic data and CIFAR-10, demonstrating consistent Gaussian behavior across settings and architectures.
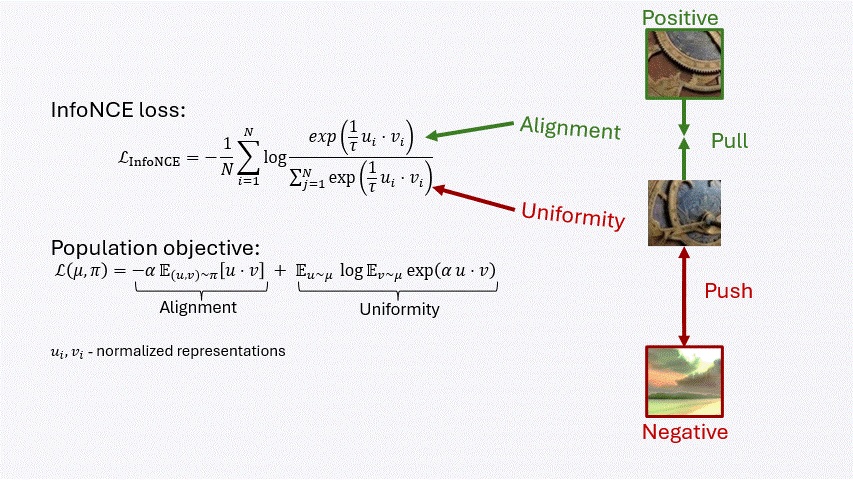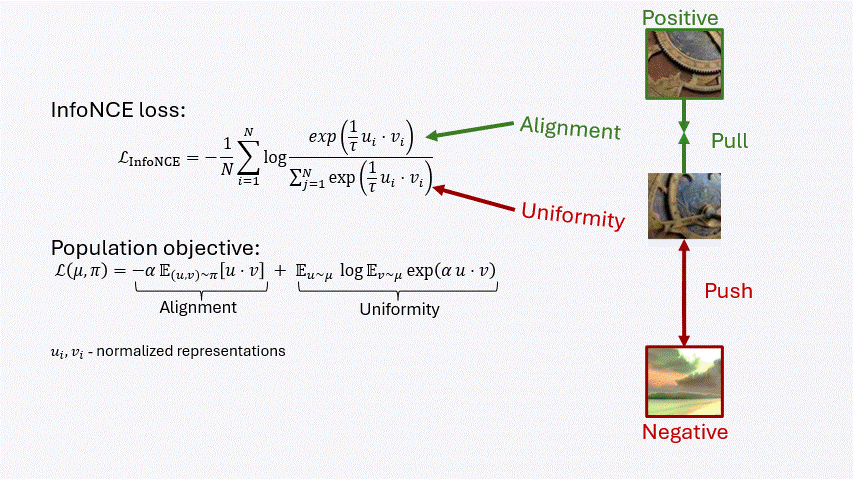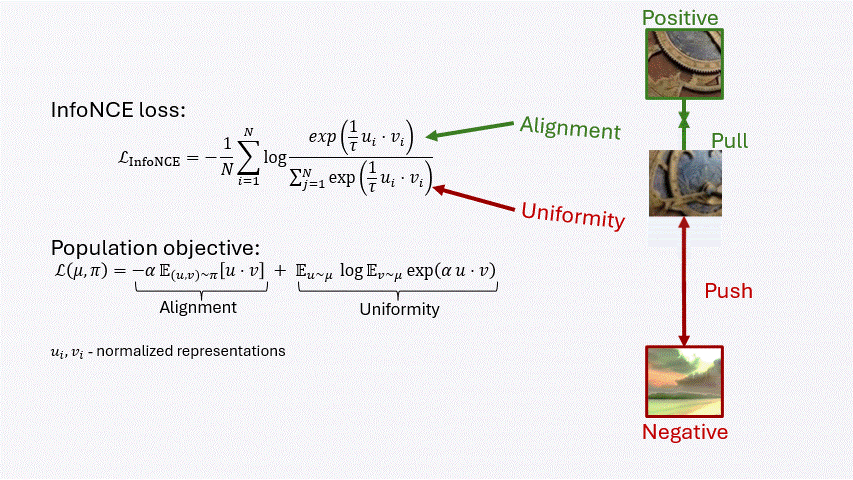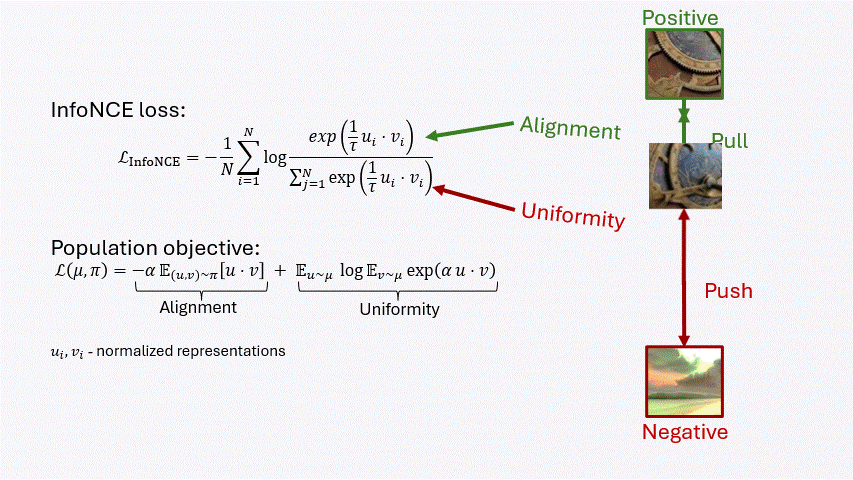
Contrastive learning balances two forces: alignment pulls positive pairs together, while uniformity spreads representations across the space.

A classical high-dimensional Lemma is that projections of points distributed uniformly on the sphere are approximately Gaussian. This provides the bridge from spherical uniformity to Gaussian behavior in representation coordinates.
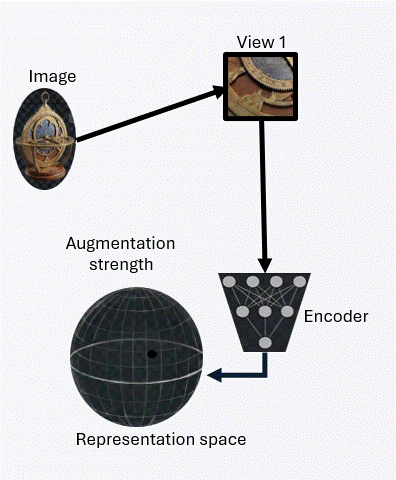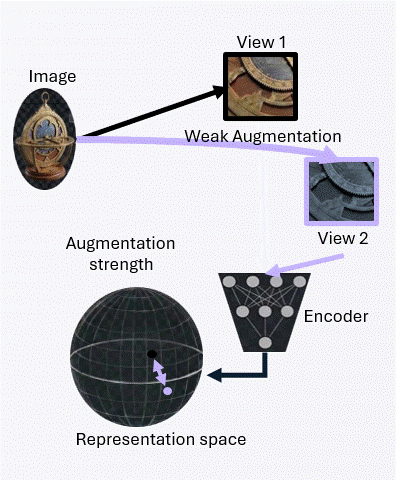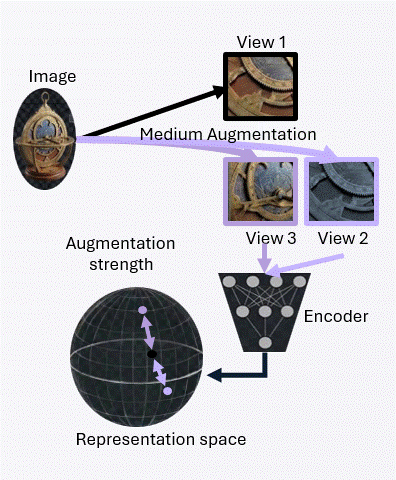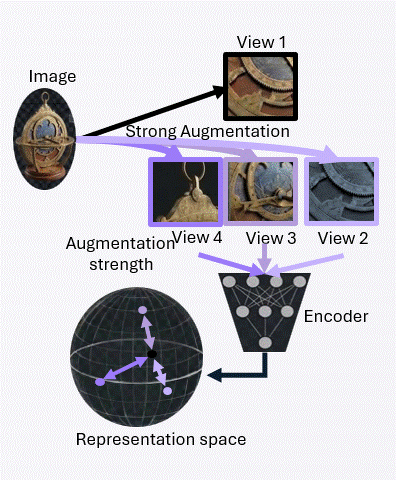
The achievable alignment is fundamentally limited by the augmentation channel. This bound formalizes how augmentation strength constrains the alignment term in the population objective.
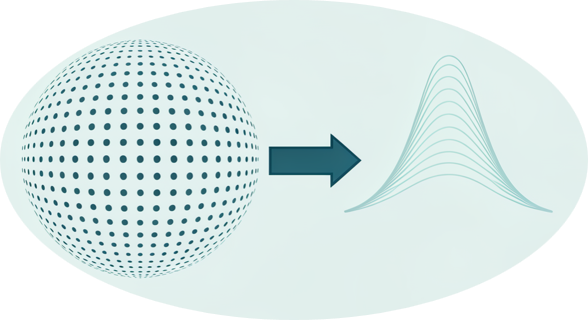
In high dimensions, the population InfoNCE objective drives representations toward a uniform distribution on the sphere. This geometric limit explains the emergence of Gaussian structure in fixed-dimensional projections.
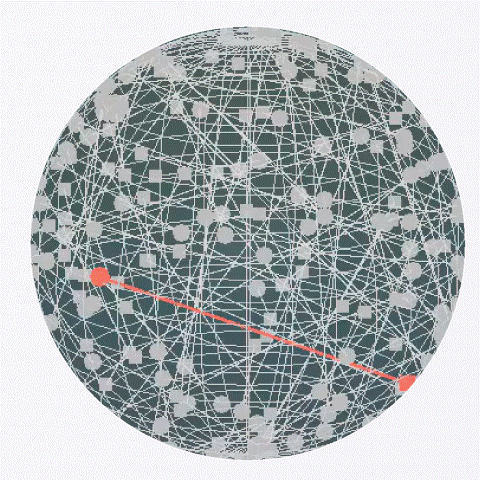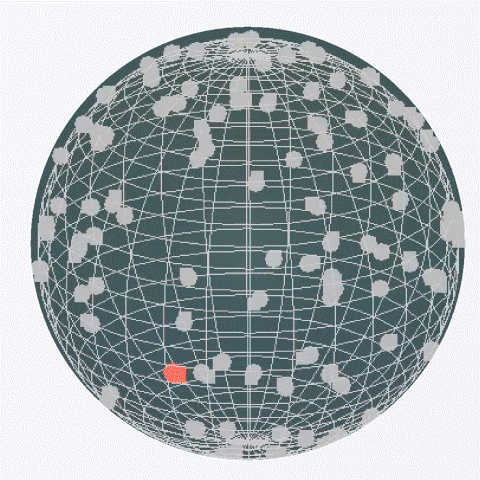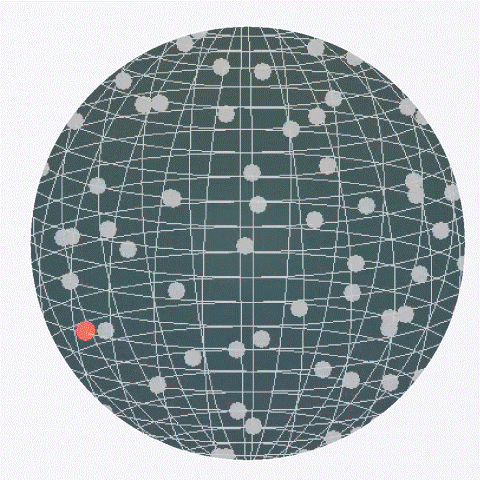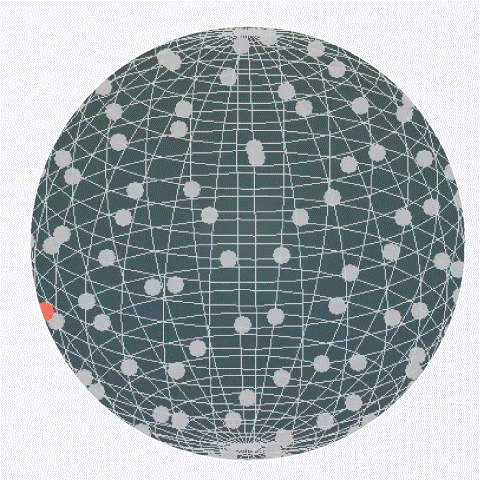
Under an empirical idealization where alignment reaches a saturated value, the objective reduces to spherical uniformity, yielding Gaussian projections asymptotically.
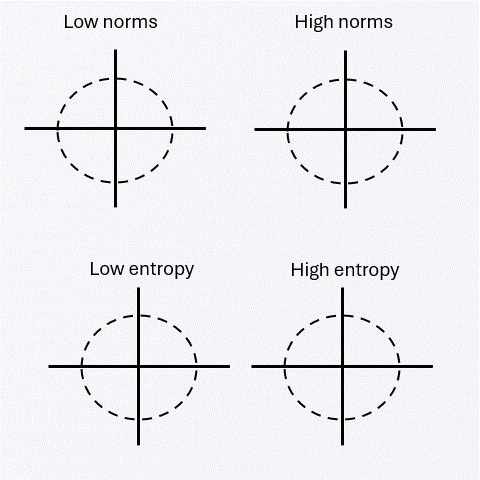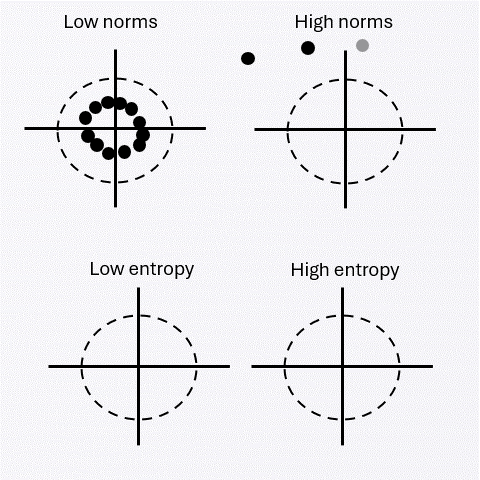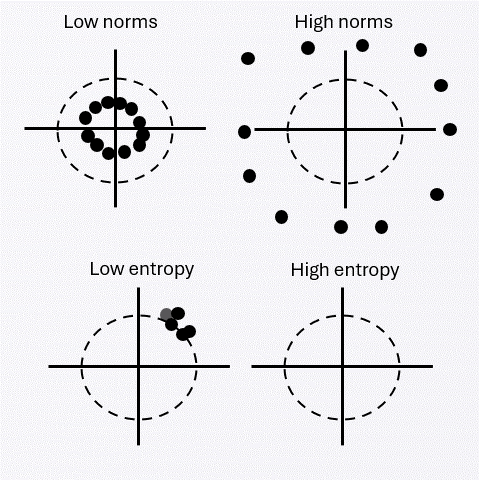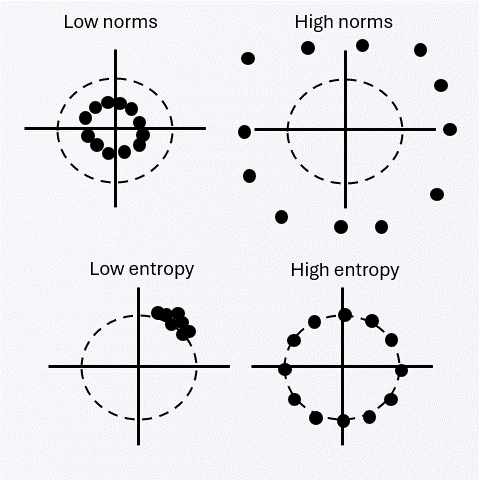
A vanishing convex regularizer favoring high entropy and low norm selects the spherical limit at the population level. This yields asymptotic Gaussian structure under the milder assumption that the alignment bound is attainable at uniformity.
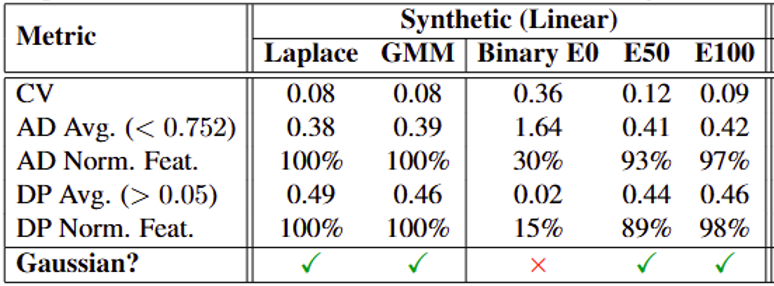
Across diverse synthetic inputs, InfoNCE training with a simple linear encoder induces norm concentration and coordinate-wise Gaussianity. This supports Gaussian structure as an emergent property of contrastive learning.
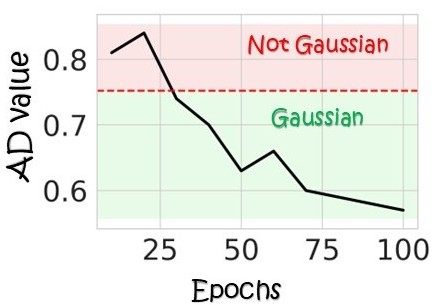
On CIFAR-10, contrastive training progressively sharpens norm concentration and makes feature coordinates increasingly Gaussian. The Gaussian trend becomes stronger as training advances.
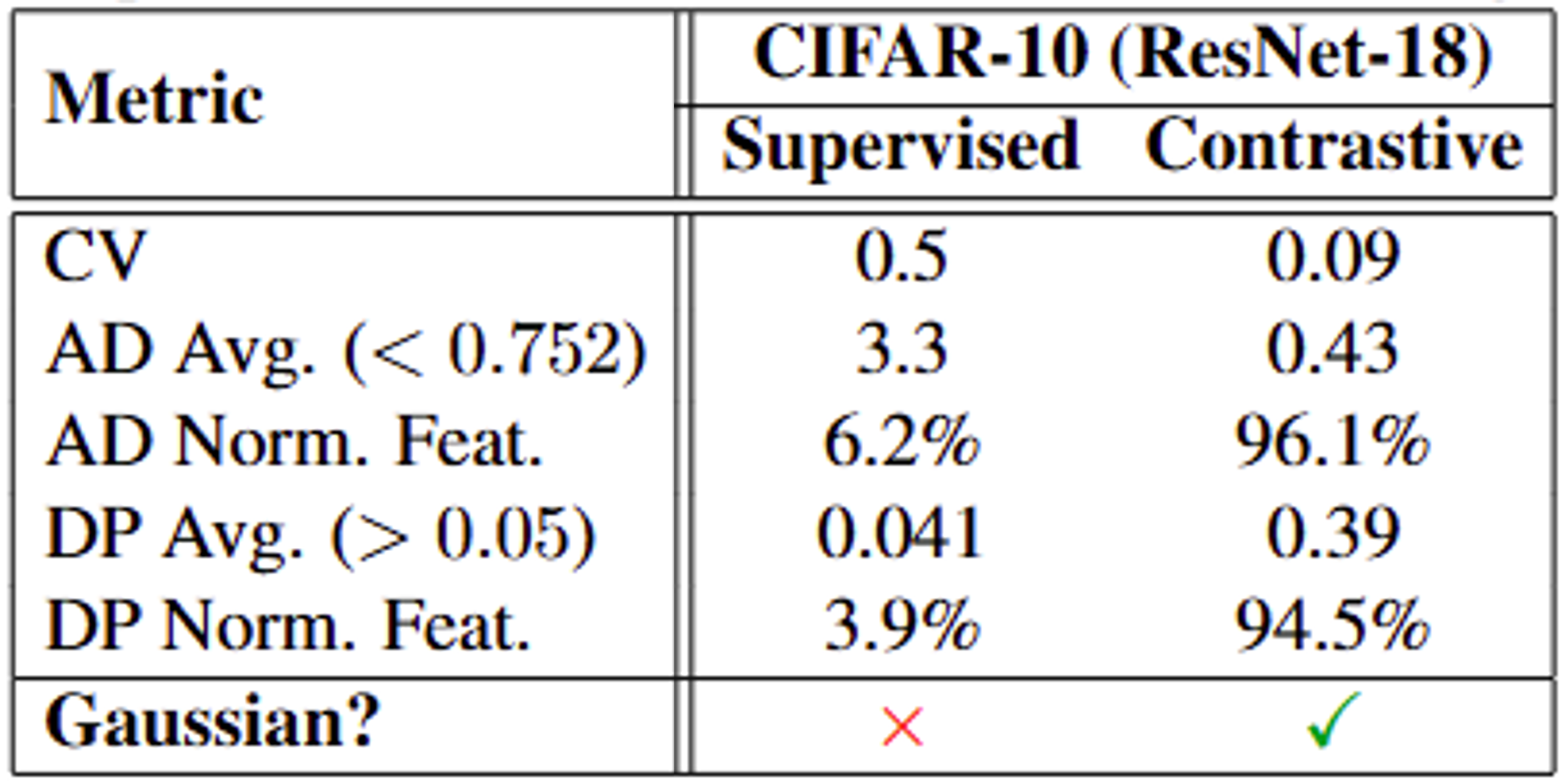
Using the same architecture (ResNet-18), contrastive training produces substantially more Gaussian representations than supervised training. This highlights that the effect is tied to the contrastive objective rather than to architecture or data alone.
@inproceedings{betser2026infonce,
title = {InfoNCE Induces Gaussian Distribution},
author = {Betser, Roy and Gofer, Eyal and Levi, Meir Yossef and Gilboa, Guy},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026}
}